

by Dan Lorts (STEM-Trek Blogger and HPC Advocate)
Well Monday at SC18 started off in typical fashion; I arrived late, thanks to lovely Dallas traffic and the fact that everyone forgets how to drive when it’s raining.
I checked in after walking a ‘short’ distance, which at the Dallas Convention Center is a hike at times, and was greeted by a conference center employee who, because I was using my cane, took me straight to the front of the registration desk and promptly checked me in without any problems.
Then there was the first major decision everyone must make at SC18…which lanyard was I going to pick up and use for my badge? It is a tough decision (not enough scientific data…). I picked up two; Micron and Cray since they were kind to support STEM-Trek’s SC delegation this year.
Another attendee was having the same difficulties and so I explained that I picked up two so that I have a backup…she liked that justification and grabbed two herself. If there are any remaining at the end of the show I may need some additional “backups.”
I made my way to the meeting rooms where the tutorials were being held. Prior to SC18, I had gone through the schedule options (which is not an easy chore) and chose to initially sit in on the “Application Porting and Optimization on GPU-Accelerated POWER Architectures” tutorial. The room was about 75 percent full. Approximately 50 percent were working on their laptops. Most were following a login to the POWER9 enabled supercomputer, Ascent (Fig 1) at Oak Ridge National Lab (handout with account creation instructions provided upon entering the room). The sample program they were using for the hands-on exercise was the Jacobi problem (Fig 2).

Figure 1.

Figure 2.
The presenter walked everyone through the implementation of the algorithm. As we worked on the problem, he presented a slide comparing the computational measurements of the POWER9 components of ASCEND) and also the Tesla V100 components from NVIDIA (Fig 3).
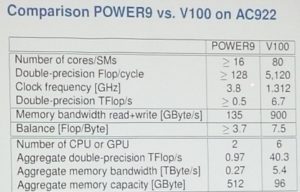
Figure 3.
It was interesting to note, from Fig. 1, that if a person only looked at the number of cores a particular processor contains they would totally think that the more cores a device has that the higher its performance. This simpleton approach was appropriate back in my days of the dinosaurs when the maximum number of processors a device contained could be counted on one hand. Today, with higher levels of integration, each core of a multicore device has multiple cores itself and at some point the hierarchy will only get deeper.

Figure 4.
One final note of interest, at least to me it was interesting, was the level of detail that chip manufacturers have integrated into the device for performance monitoring. An example providing some of the internal performance counters of the POWER9 is shown in Fig 4. It was mentioned by the presenter that there has always been ‘internal registers and functionality’ within the device but it was primarily for diagnostic purposes during the development. A user was satisfied with the external APIs to determine performance such as ‘printf’ statements and ‘wall clock’ measurements because the devices weren’t that high performance and these tools were sufficient. Now that the devices are much more complicated and run at higher speeds, we must allow measurements further down into the metal, as they say.
Cover image from the Dallas Kay Bailey Hutchison Convention Center.
Watch UbuntuHouse@SC18 sponsors’ and friends’ websites to see what they will be doing at SC18!
 |
 |
|---|
![]()


